
TMW #103 | Reverse ETL in a changing data ecosystem
Welcome to The Martech Weekly, where every week I review some of the most interesting ideas, research, and latest news. I look to where the industry is going and what you should be paying attention to.
👋 Get TMW every Sunday
TMW is the fastest and easiest way to stay ahead of the Martech industry. Sign up to get the full version delivered every Sunday for this and every TMW, along with an invite to the TMW community. Learn more here.
When I first started hearing about this growing category of Reverse ETL, I was skeptical. My knowledge at the time was that the category was about offering CDPesque features without the database that CDP companies rely on. Reverse ETL instead utilizes a company’s existing data warehouse and data modeling tools as the basis for data activation. My big hesitation was this – does this mean we’re going back to IT managing the data architecture that makes online marketing work?
Over the past two weeks Segment Twilio and mParticle both market-leading CDP offerings, announced their own iteration on Reverse ETL. Segment has introduced Profiles sync, as a way to integrate customer profiles in Segment with data warehouse records, while mParticle is offering traditional reverse-ETL flows with native identity resolution and real-time data streaming. Given that the premise of Reverse ETL is about offering an alternative to data activation to CDPs, both of these announcements point to the inevitable – the Reverse ETL trend has come. But what’s driving it?
After spending time understanding the category, its founders, and the changing landscape of modern data management, I have come to appreciate the concept of Reverse ETL as one piece in a fundamentally new way to think about customer data orchestration.
As Tejas Manohar, Co-CEO at Hightouch Data - one of the early category leaders, mentions in a blog post reflecting on the recent announcements by both Segment and mParticle, the situation in the data ecosystem may be changing faster than we think:
In the last few months, it’s become evident that Reverse ETL has crossed the chasm. It’s hard to believe that just a few years ago, data leaders regularly asked us, “why would you want to use the data warehouse as a source?” Fast-forward to now, and every day new enterprises come to us saying, “well, the data warehouse is already our source of truth. We’re interested in learning how Hightouch can help us put that data to work.”
Data powerhouses
In the bundled warehouse I explained that one of the drawbacks of reverse ETL is that cloud data platforms are still early in enterprise business. Spending is about 11% according to Gartner. For a market segment that would make the most use of a Reverse ETL tool, it may be too early.
The other side of this is that data platforms are on an ongoing growth path. In Q1 2022, the major cloud platforms offering data warehousing drove more than $191 billion over 2021, with year-on-year growth in Q1 2022 of 34%, driven primarily by the top three platforms – AWS, Azure, and Google Cloud Platform. Right now data storage and management are increasingly moving towards these big three platforms as they aggressively push into business operations, taking up more than half of the total cloud platform market share in 2022.
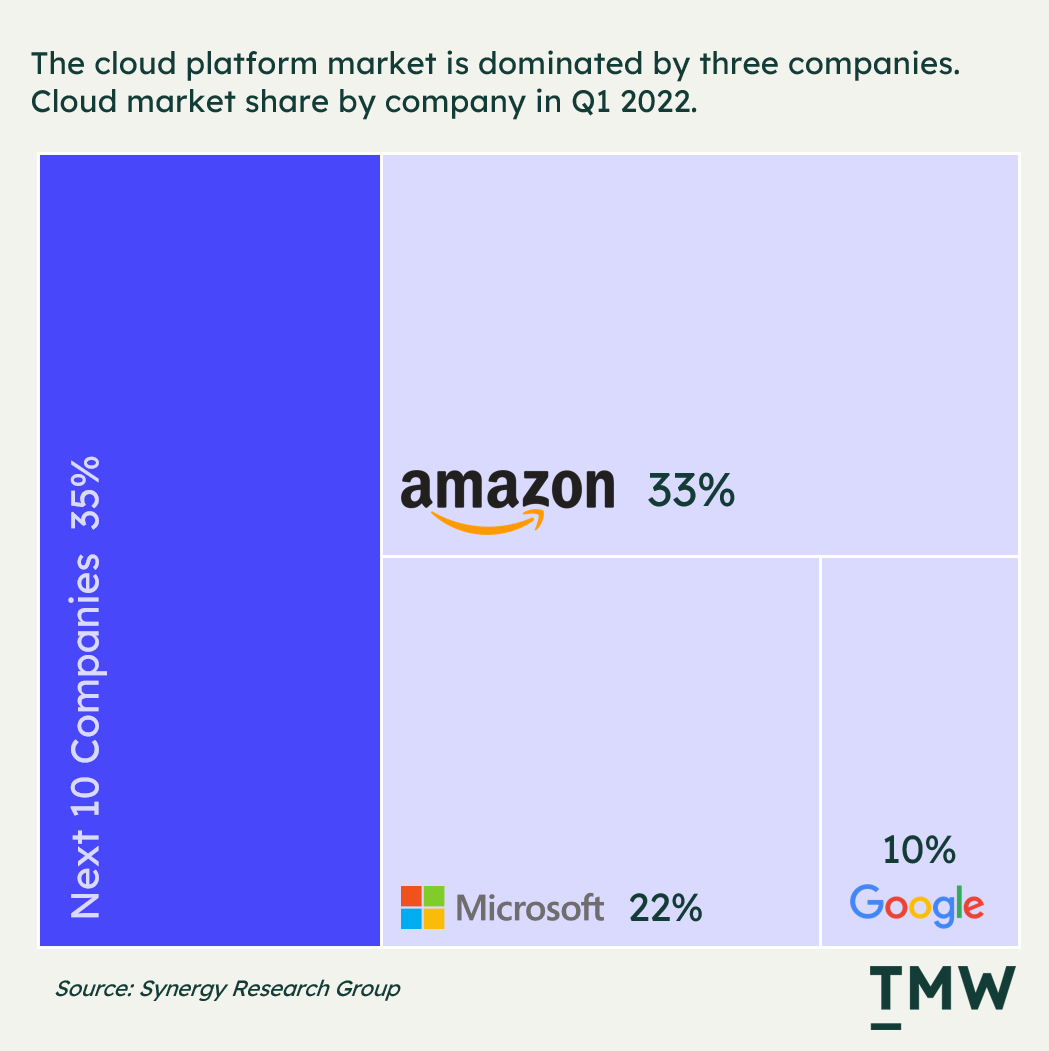
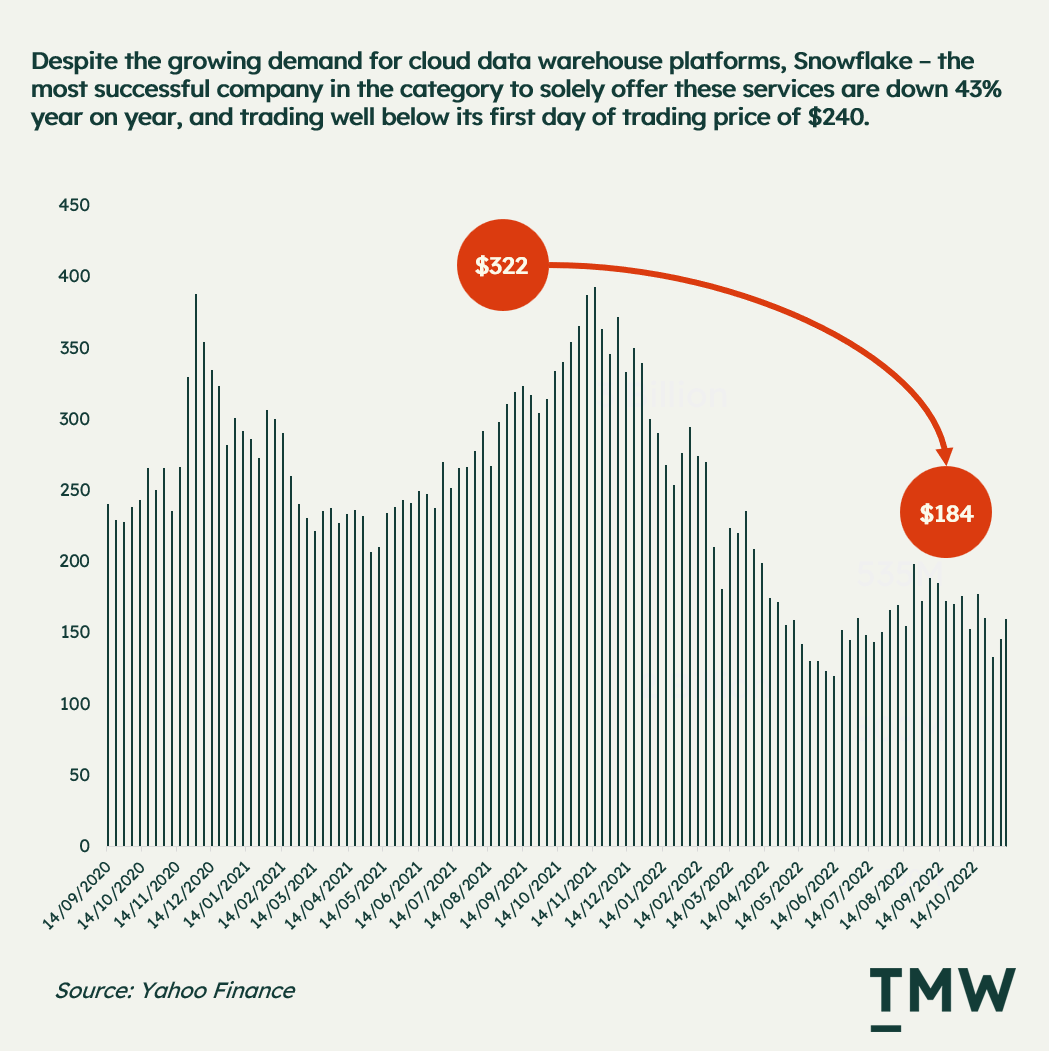
But it’s not all growth. While the big three take the lion's share of the market, Snowflake is down 43% percent year on year, at a price lower than its first day of trading. Back in 2020, Snowflake debuted at twice the valuation of Zoom (in the middle of the pandemic!) and was touted as one of the most significant cloud platforms to enter the public markets.
Disappointing quarterly targets, and a slowing market after the pandemic means there are headwinds for cloud technologies like Snowflake. Regardless, the company’s role in the data ecosystem as an individual cloud platform provider should not be understated, but the story isn’t all growth right now.
Another angle on this is the sheer amount of people building skills in the cloud platform space. According to the Cloud Native Computing Foundation (CNCF) in 2019, there were more than 6.5 million developers actively working on cloud-native applications globally, up more than 1.8 million the year before.
More people means more applications which means more usability and flexibility for whatever a marketer wants to do on top of the data warehouse. But there’s an alternative that’s also been growing over the past ten years. And that’s the enterprise marketing suite.
Warehouse native vs Marketing suite
Even though the Reverse ETL category is emblematic of the shift towards the data warehouse as a source of truth for customer data, data activation is only one slice of the entire marketing technology stack that is changing.
Enterprise data orchestration is moving in two directions – marketing suite and warehouse native. Both of them have tradeoffs and unique value as companies progress data maturity:

On one side you have companies embracing the Adobe, Salesforce or Oracle marketing cloud suites promising to bring all your customer analytics, data, and experience management tools into one environment. Over the 2010’s the goal for the larger cloud companies has been to slowly acquire and integrate various technologies to achieve this. Sparrow One, in their prescient analysis in 2020 describes the shift to marketing suites like this:
“This vertical approach to solving all marketing and advertising needs via a single suite was a good fit for its time. It supported the premise of 1:1, personalized marketing designed to rapidly and cost-effectively move consumers through the funnel, from awareness all the way to loyalty and advocacy, while aggregating enough data along the way to identify what’s working and what isn’t.”
After ten years of strategic acquisitions that have built out these behemoth marketing monoliths, the results have been mixed, but the fundamental problem still persists for data management. Even though marketers can enjoy creating a segment of customers in Adobe Analytics to push into an experiment or an email list, or matching email marketing lists with CRM records, the efficiency of being able to do that still betrays the fact that these platforms need to host your data somewhere.
The data warehouses that these various enterprise suites run on are usually on AWS, Azure, Akamai or Oracle cloud. The problem is that those environments are usually separated from the rest of the company data that’s collected in the data warehouse. On top of this, trying to extract raw data to send it to core systems is also a difficult and often expensive task. Not your house, not your data.
The same premise applies to CDPs. CDPs allow for greater integration between applications and the ability to resolve customer identity. In some ways CDPs break the barriers by helping with the integration problem in most brands, but when it comes to operational or other types of business data it becomes a blocker.
One of the main criticisms leveled at CDPs is the lack of support for operational data and core customer records because most CDPs rely on events-based architecture that doesn’t fully align with what is in a data warehouse.
The killer feature for Reverse ETL applications and the increasing shift towards data warehouse-based applications is they can bring all kinds of data into the warehouse. Does this shift mean the technology is less accessible to marketers? It probably does. Does it mean that companies have greater control and connectivity between their applications? It probably does. Is computing costs with a data warehouse more expensive? Yeah probably.
The Martech of the 2010’s was solving the skills gap in marketing with simplified and easier-to-use marketing technologies. The 2020’s is going in the other direction. The rise of Marketing Ops as a technical marketing role, maturing digital departments, and greater familiarity with how data and technology work will be the defining trait of this decade.
And that’s why the warehouse as CDP argument makes sense – greater control over your customer data means greater complexity. But there are actual people now that can deal with this complexity and understand the needs and use cases of the marketing department.
You could argue that both sides of data orchestration are servicing different needs, but this is now blurring. As Miles Younger suggests, major cloud platforms like Snowflake, Google Cloud Platform, and AWS already have primitive marketing solutions that integrate directly with the data warehouse.
It’s not lost on me how AWS is moving into advertising so quickly with retail media and recent partnerships with Liveramp and other platforms. AWS can offer a “marketing suite” by centralizing data in the warehouse that most companies are already using, an attractive proposition for AWS users. Even Snowflake gives step-by-step instructions to build a CDP on their platform.
The only wrinkle is that companies that invest in cloud architecture tend to be primarily software, data analytics-based companies, or banks. This means that the CDP value proposition that buying the tooling and the database it runs on for less sophisticated companies holds true for now.
In this way, CDPs are like a bridging technology as companies continue to grow their own digital maturity they will want features and capabilities that are constrained by both CDPs and marketing suits.
Simplicity vs constraint vs flexibility vs complexity
Warehouse native applications like Reverse ETL within cloud platform ecosystems are strong contenders against going all in on a marketing suite. There’s greater flexibility with the right level of technical talent involved, and more adaptability to a company’s specific use cases and needs. But more work is needed if applications can be fully used and accessible to marketing teams. If cloud platforms can figure this out, then there’s a good chance that the trend toward warehouse native applications is one that will fundamentally change the industry over the next decade.
I think what’s lost in the arguments between the Reverse ETL companies and the CDP companies is that Reverse ETL is only just the activation layer of the customer data platform, not a replacement for CDPs. Instead, the Reverse ETL category in this space is advocating for the data warehouse to become the true source of customer data for enrichment, identity resolution, and profile creation.
There’s always going to be a market for CDPs and marketing suites, but as more companies embrace the cloud, expect this narrative to change. Brands that fully control their customer’s data will have the advantage because not being able to build things for your customers because you’re constrained by a vendor is a losing strategy.
It’s still early, but technical marketing talent is on the rise, the cloud is growing and so are the ecosystems that support modern marketing. Reverse ETL will play a crucial role in mainstreaming warehouse-native Martech stacks.
What you get for simplicity you pay for with constraint, and what you get for flexibility you pay for with complexity. This is the equation that’s running in the mind of buyers of marketing clouds, CDPs, and cloud-native applications and that’s exactly why I think that Reverse ETL is driving a significant paradigm change for how modern customer data architecture will be built and managed.
Stay Curious,
💼 The market review preview:
- Meta layoffs: How Zuckerberg explains letting 11,000 people go
- New privacy policies: Australia's grappling with crippling privacy breaches
- Bytedance's dominance: What happens when an AI company gets into social media
- The rise of partner ops: From edge case to business case
- Everything else: Today in Muskistan, Substack gets more annoying, lesser-known No Code solutions, AI prompt battles, and many other topics....
Get the Wednesday Market Review email with a TMW PRO Subscription. It's the easiest way to stay updated on the marketing technology industry. Try it for free for 30 days.
Make sense of marketing technology.
Sign up now to get TMW delivered to your inbox every Sunday evening plus an invite to the slack community.
Want to share something interesting or be featured in The Martech Weekly? Drop me a line at juan@themartechweekly.com.